‘Q i-jtb the Raven’: Taking Dirty OCR Seriously
The following is a talk I will deliver on January 9, 2016 for the Bibliography and Scholarly Editing Forum’s panel at MLA 2016. It is part of a longer article in progress.
On November 28, 1849 the Lewisburg Chronicle, and the West Branch Farmer published one of the most popular poems of the nineteenth century, Edgar Allan Poe’s “The Raven.”

The November 28, 1849 Lewisburg Chronicle, and the West Branch Farmer
The Lewisburg Chronicle’s “Raven” is one version among many printed after Poe’s death in 1849—“By Edgar A. Poe, dec’d”—interesting as a small signal of the poem’s circulation and reception. It is just such reprinting that we are tracing in the Viral Texts project, in which we use computational methods to automatically surface patterns of reprinting across nineteenth-century newspaper archives.
And so this version of the poem also becomes interesting as a digitized object in the twenty-first century, in which at least one iteration of the poem’s famous refrain is rendered by optical character recognition as, “Q i-jtb the Raven, ‘Nevermore’” (OCR is a term for computer programs that identify machine-readable words from a scanned page image, and is the source for most of the searchable data in large-scale digital archives). What is this text—this digital artifact I access in 2016? Where did it come from, and how did it come to be?
Such questions are particularly acute as researchers increasingly leverage digitized archives through computational text and image analysis. As a complement to such analyses we require more robust methods for describing digital artifacts bibliographically: accounting for the sources, technologies, and social realities of their creation in ways that make their affordances and limitations more readily visible and available for critique. Matthew Kirschenbaum has named such practices “forensics,” while Bonnie Mak has suggested “an archaeology that excavates for consideration the discursive practices by which digitizations are produced, circulated, and received.”[1][2]

A sample of the OCR-derived text for “The Raven” in the CA Lewisburg Chronicle, including the line that gives this talk its title.
Discussions of large-scale digital text archives inevitably return to the question of the OCR-derived text data that underlies them. Depending on the type, age, and conditions of its given historical texts, as well as on the procedures, hardware, and software of their digitization, OCR quality in large-scale archives ranges widely. The consequences of “errorful” OCR files, to borrow a term from computer science, influence our research in ways by now well expounded by humanities scholars, inhibiting, for instance, comprehensive search. Were I to search “Quoth the Raven” in the Chronicling America database, its search engine would not find the line that gives me my title. However, critiques that both begin and end with the imperfections of the digitized text signal a foreshortening of the bibliographic imagination, in which the digital archive can be only a transparent window into the “actual,” material objects of study.
Our primary perspective on the digitized text thus far has been that of the textual critic who is entirely “concerned with…the reconstruction of the author’s original text.” As W. W. Greg contended in 1932, however, “criticism may just as rightly be applied to any other point in the transmission of the text.” For Greg, the bibliographer’s concern must be “the whole history of the text” in which “the author’s original is but one step”—albeit likely an important step—“in the transmission.” Greg describes “the text” not as a single individual, but instead as a lineage:
We have in fact to recognize that a text is…a living organism which in its descent through the ages, while it departs more and more from the form impressed upon it by its original author, exerts, through its imperfections as much as through its perfections, its own influence upon its surroundings.[3]
In the five decades since its publication, Greg’s notion of the text has significantly influenced work in bibliography, book history, and even critical editing. Theories of the variorium text, the fluid text, and the social text have refined a vocabulary for discussing transmission, circulation, and difference as essential features of any literary work. Scholars have experimented with ways to represent fungible texts both in print, such as John Bryant’s “fluid text” edition of Moby-Dick (Longman 2009), and using digital tools, such as NINES’ Juxta Commons collation platform.[4] While scholars revel in revealing the fluidity of texts from the hand- and machine-press eras, however, we rarely note—except, perhaps, to dismiss them—the variora emerging online. Just as cheap, pirated, and errorful American editions of nineteenth-century British novels now teach scholars much about the economics, print technology, and literary culture in that period, dirty OCR illuminates the priorities, infrastructure, and economics of the academy in the late 20th and early 21st centuries.
There is a growing body of literature around the bibliographic description of born digital materials, such as Kirschenbaum’s analysis of William Gibson’s electronic poem Agrippa in Mechanisms, or the “Preserving Virtual Worlds” team’s attempts to apply a FRBR (functional requirements for bibliographic records) model to classic computer games such as Mystery House, ADVENTURE, and Spacewar! The PVW team notes that “even the simplest electronic ‘text’ is in fact a composite of many different symbolic layers” and the same is true of the digitized historical text.[5]
The mass-digitized book, newspaper, or magazine is never simply a transparent surrogate for a corresponding physical object. It is instead a new edition—in the full bibliographic sense of the word—which, while it “departs more and more from the form impressed upon it by its original author,” nonetheless ”exerts, through its imperfections as much as through its perfections, its own influence upon its surroundings.“ As Belanger describes, “[a]n edition of a book is all copies printed at one or later times from the same setting of type.”[6] While the image of a particular digitized text provided by an archive may reflect precisely the setting of type in the edition from which it was scanned, the computer-readable text was created by OCR software, or “reset,” from the image-original. We might think of OCR as a species of compositor: prone to transcription errors, certainly, but nonetheless resetting the type of its proof texts into .txt or .xml files rather than printer’s frames.
In arguing that those text files constitute new editions, I am not particularly bothered by the fact that OCR is an “automatic” process, while composing type is a “human” process. To maintain such a dichotomy we must both overestimate the autonomy of human compositors in print shops and underestimate the role of computer scientists in OCR. Both movable type and optical character recognition, along with a host of textual technologies in between, attempt to automate laborious aspects of textual production. Indeed, we can only speak of editions as such, whether printed or digital, within an industrialized framework. The very concept of the edition only pertains when sets of identical copies can be produced for a given book. During print’s infancy it was decried as mechanical or inhuman, as in 1492 when Johannes Trithemius claimed—in a book he promptly had printed—that “Printed books will never be the equivalent of handwritten codices, especially since printed books are often deficient in spelling and appearance. The simple reason,” Trithemius insisted, “is that copying by hand requires more diligence and industry.”[7] When print was less familiar, in other words—during the period Alan Liu might call “the unpredictable zone of contact” between manuscript and print culture—its errorful industrialism was as apparent to scholars as that of OCR is to us now.[8] Moreover, by speaking of OCR as an “automatic” process, we elide a substantial sub-field of research by colleagues in Computer Science. While OCR certainly automates certain acts of transcription, it does so following constantly-developing rules and processes devised by human scholars.[9]
In order to reorient ourselves toward the digitized archive, we must reckon with its constituent parts and take seriously its digitality. In my remaining time I will outline some steps toward such a method using the November 28, 1849 Lewisburg Chronicle, in hopes this focus will seed thinking about the larger archive from which it is drawn. While some of the steps I describe may seem self-evident, I suggest they are not to a good many scholars working in digital archives, and that even such obvious steps are elided when scholars treat—and cite—digitized sources as transparent surrogates rather than new editions.
1. First, CA’s interface offers relatively little information about particular newspaper issues. The only prominent metadata lists a newspaper’s name, issue date, and the image number of the displayed page. Clicking on the name of the newspaper just below the title—where, in this case, it reads “About Lewisburg Chronicle…”—brings users to a longer catalogue and narrative description of the print edition of this newspaper. These prose narratives were written for each CA newspaper by the awardees who digitized them—more on awardees soon—and offer insight into the aims, audience, and affiliations of the papers.
To glean more details about a particular newspaper’s CA digitization, users can click the link at the bottom right of a newspaper’s page—where it reads in this instance “Provided by Penn State…”—to learn more about the papers contributed by a specific awardee. From the awardees page for the Penn State University Libraries, one can browse the batches they have contributed to CA and learn that the November 28, 1849 issue of the Lewisburg Chronicle was uploaded in batch_pst_fenske_ver02 on July 9, 2013 at 8:07pm.[10] This metadata is all that CA provides for any given issue directly through its interface.
2. We can learn more about the digitization process for an issue in CA by downloading its JPG and PDF files. While the images themselves reproduce the historical page, there is much more information about the files and their creation in their Exif (Exchangeable Image File Format) data. There are a range of methods for reading Exif data. Using the command line application Exiftool on the JPG and PDF of our sample Lewisburg Chronicle issue, for instance, we see the following:[11]
JPF Exif metadata
ExifTool Version Number: 10.01
File Name: seq-1.jp2
Directory: .
File Size: 4.5 MB
File Modification Date/Time: 2015:12:10 15:55:47+01:00
File Access Date/Time: 2015:12:11 13:37:35+01:00
File Inode Change Date/Time: 2015:12:10 15:55:48+01:00
File Permissions: rw-r-----
File Type: JP2
File Type Extension: jp2
MIME Type: image/jp2
Major Brand: JPEG 2000 Image (.JP2)
Minor Version: 0.0.0
Compatible Brands: jp2
Image Height: 6997
Image Width: 5412
Number Of Components: 1
Bits Per Component: 8 Bits, Unsigned
Compression: JPEG 2000
Color Spec Method: Enumerated
Color Spec Precedence: 0
Color Spec Approximation: Not Specified
Color Space: Grayscale
Warning: Can't currently handle huge JPEG 2000 boxes
Image Size: 5412x6997
Megapixels: 37.9
PDF Exif Metadata
Ryans-MacBook-Pro:downloads rcc$ exiftool seq-1.pdf
ExifTool Version Number: 10.01
File Name: seq-1.pdf
Directory: .
File Size: 826 kB
File Modification Date/Time: 2015:12:10 15:55:50+01:00
File Access Date/Time: 2015:12:10 16:10:22+01:00
File Inode Change Date/Time: 2015:12:10 15:55:55+01:00
File Permissions: rw-r-----
File Type: PDF
File Type Extension: pdf
MIME Type: application/pdf
PDF Version: 1.4
Linearized: No
Page Count: 1
Page Mode: UseNone
Format: application/pdf
Title (en): Lewisburg Chronicle, and the West Branch Farmer..(Lewisburg, Pa.) 1849-11-28 [p ].
Description (en): Page from Lewisburg Chronicle, and the West Branch Farmer. (newspaper). [See LCCN: sn85055199 for catalog record.]. Prepared on behalf of Penn State University Libraries; University Park, PA.
Date: 1849:11:28
Type: text, newspaper
Identifier: Reel number 0028077635A. Sequence number 50
Create Date: 2012:01:18 12:56:08-07:00
Producer: itext-paulo-138 (itextpdf.sf.net-lowagie.com)
Modify Date: 2012:01:18 12:56:08-07:00
As we can see these examples, some metadata recurs in the Exif metadata for each file, while some is unique to one file or the other. In this case, the JPG’s Exif metadata mostly describes the JPG file itself: its size, resolution, color profile. The PDF Exif metadata, by contrast, details when the file was originally created, to the second (January 18, 2012); the microfilm reel from which it was scanned (Reel number 0028077635A); and even the software package that created it (itext-paulo–138). iText is a software package for managing large-scale PDF creation, and it uses the ABBYY Finereader OCR software.
3. There is one additional image file from which scholars can glean information about CA’s digitized newspaper editions, though one must read the NDNP’s Technical Guidelines to realize it exists.[12] According to those guidelines, each issue uploaded to CA must include an archive-quality TIFF file. That latter file is not served to users as part of Chronicling America’s interface, likely because they are quite large files and it would be server-intensive for too many users to download them frequently. To obtain the archive-quality tiff of this Lewisburg Chronicle issue, I wrote directly to the Library of Congress; after a few days a librarian sent me a link through which I could download the TIFF.
The TIFF file’s Exif metadata includes yet more information about how this issue was digitized and is the only place that lists the scanner model used for digitization: the Eclipse 300D microfilm scanner.[13]
TIFF Exif Metadata
ExifTool Version Number: 10.01
File Name: 0050.tif
Directory: .
File Size: 36 MB
File Modification Date/Time: 2015:12:10 20:34:01+01:00
File Access Date/Time: 2015:12:11 14:25:24+01:00
File Inode Change Date/Time: 2015:12:10 20:34:01+01:00
File Permissions: rw-r-----
File Type: TIFF
File Type Extension: tif
MIME Type: image/tiff
Exif Byte Order: Little-endian (Intel, II)
Subfile Type: Single page of multi-page image
Image Width: 5409
Image Height: 6997
Bits Per Sample: 8
Compression: Uncompressed
Photometric Interpretation: BlackIsZero
Fill Order: Normal
Document Name: 0028077635A
Make: Eclipse
Camera Model Name: Eclipse 300D,SN# sn632129
Strip Offsets: 493
Orientation: Horizontal (normal)
Samples Per Pixel: 1
Rows Per Strip: 6997
Strip Byte Counts: 37846773
X Resolution: 300
Y Resolution: 300
Planar Configuration: Chunky
Resolution Unit: inches
Page Number: 0 1
Software: iArchives, Inc., 3.240
Modify Date: 2012:01:18 12:55:32
Artist: Penn State University Libraries; University Park, PA; iArchives
File Source: Unknown (microfilm)
Image Unique ID: 50
Image Size: 5409x6997
Megapixels: 37.8
This might seem a mundane detail, but I would argue it is just as important to a full understanding of this text as knowing the printing press is to a full understanding of a printed book.
4. Next, we can learn a few new details from the XML (eXtensible Markup Language) file of this newspaper page. The location of this file is not obvious, though one can find it on the CA website. In short, one must scroll to the bottom of the “Text” file provided in the main menu (where the JPG and PDF can be found) where one finds a link to the XML file.[14] The Lewisburg Chronicle’s XML file includes important additional metadata about the OCR processing that generated the computable text of this edition.
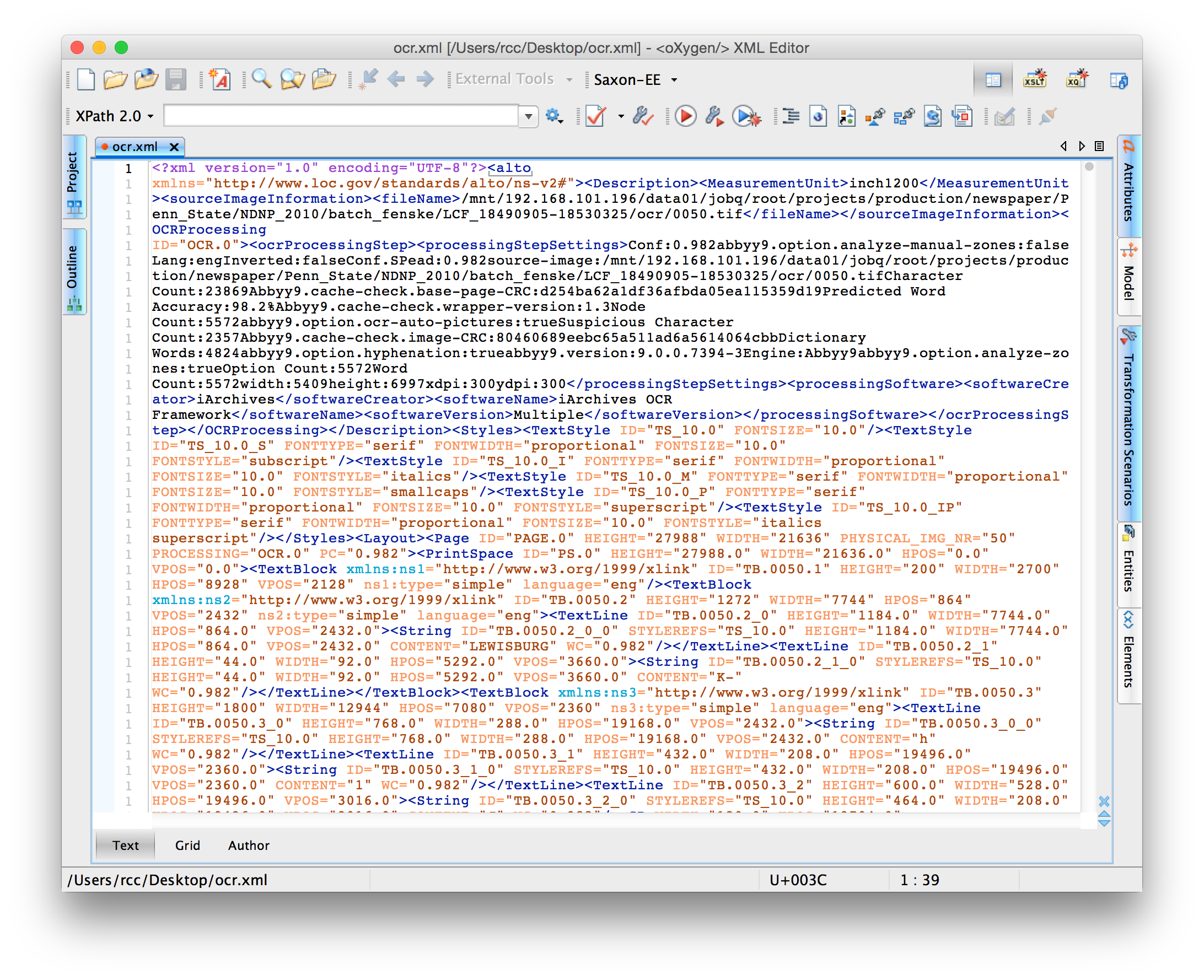
The XML file for this edition of the Lewisburg Chronicle.
These XML fields show, for instance, that the OCR was performed using the Abbyy Finereader 9 software, with a “Predicted Word Accuracy” of 98.2%.[15]
The XML also lists “iArchives OCR” as “processing software.” This reference to iArchives points us away from Chronicling America’s interface to an institutional history largely hidden from it. iArchives is a company in Lindon, Utah which many of the first grantees under the NDNP contracted to perform their scanning. This detail in the XML file, then, indicates Penn State University Library did not digitize this newspaper issue in house.[16]
I would assert that the digitized edition of the November 28, 1849 Lewisburg Chronicle, and the West Branch Farmer comprises at least six parts: an archival TIFF, a JPG, a PDF, an OCR-derived text file, an XML file, and the web interface. The image files might be classed as a species of facsimile edition, while the OCR-derived text and XML files are a new editions; all of these come together in a kind of digital variorum. Bibliographic clues are scattered among the artifact’s parts, not all of which are available through CA’s public interface.
The details gleaned from these files, however, are only one part of a full bibliographic account, which should also concern itself with the institutional, financial, social, and governmental structures that lead one historical textual object to be digitized, while another is not. In Ian Milligan’s study of newspapers cited in Canadian dissertations, he demonstrates quantitatively that overall citations of newspapers have increased in “the post-database period,” but also that those citations draw ever more disproportionately from those papers which have been digitized over those which have not: “Before digitization, a newspaper like the Ottawa Citizen was roughly equivalent in historical usage to the Toronto Star, as one might expect, given their relative prominence in Canadian history. After the Star was digitized and made available, however, it became far more prominent” in dissertations.[17] In other words, decisions about what to digitize ripple throughout the scholarly record from then on, a phenomenon we should mark in scholarship drawn from digitized texts.
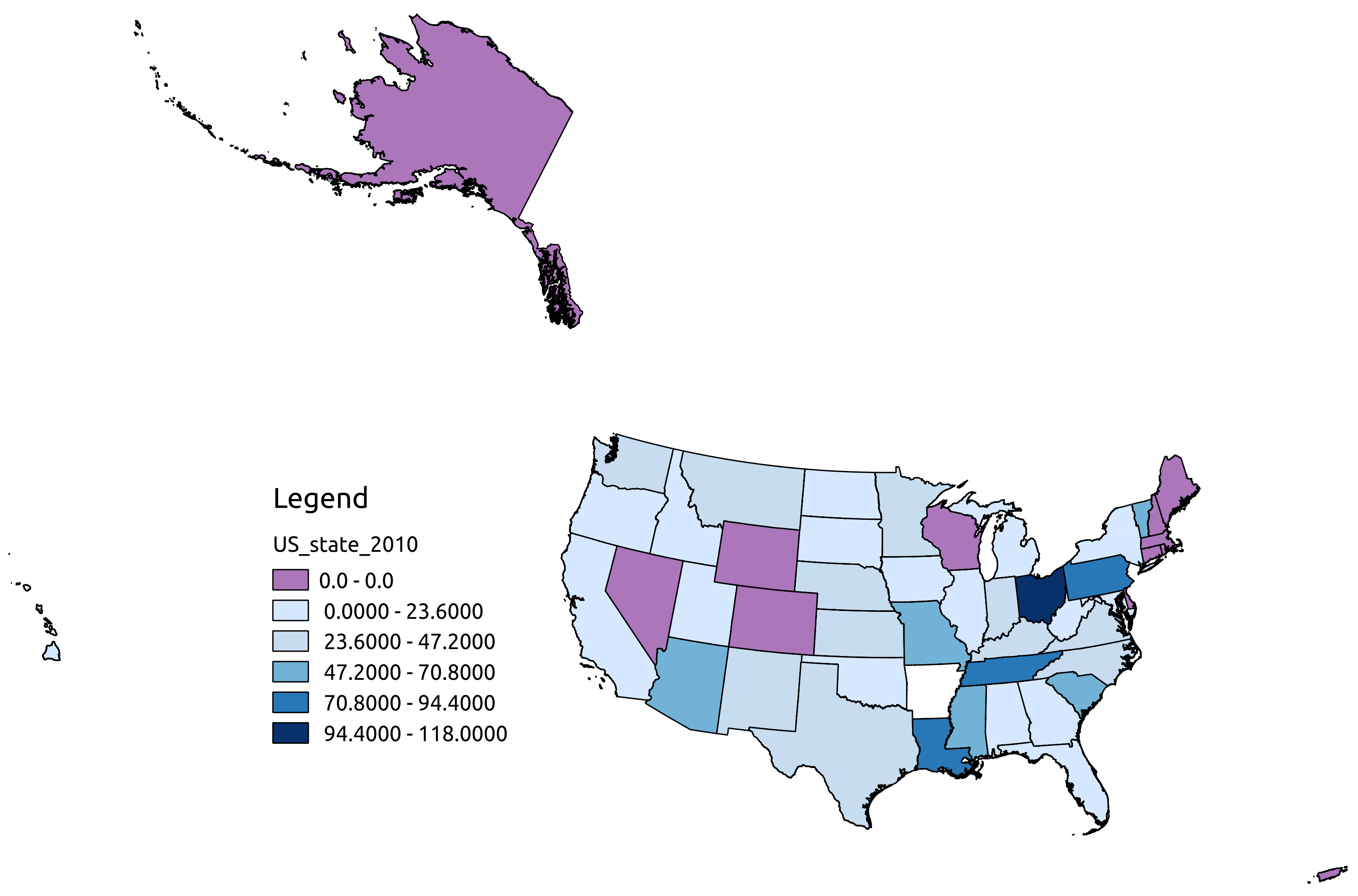
A map of state contributions to Chronicling America, prepared by Viral Texts research assistant Abby Mullen.
In the case of the Lewisburg Chronicle, understanding the decisions that led to its digitization requires delving into a range of paratexts related to the United States’ National Digital Newspaper Project (NDNP) and its grantees. By mentioning the NDNP, I highlight an essential bibliographic fact about the Chronicling America database. CA is not a single digitization project run by the Library of Congress, but the portal to data generated by the NDNP, which awards grants to groups in individual states seeking to digitize their historical newspapers. Such state-level granting, however, means that some states are well represented, others less so, while many are not represented at all. For instance, my home state of Massachusetts has not yet participated in the NDNP, meaning that CA includes no papers from Boston or other Massachusetts towns. This also means that measures of newspapers’ significance vary from state to state. In their applications for NDNP funding, groups must articulate a rationale for choosing “historically significant newspapers” from their state. While these rationales share many features, they are not identical.[18]
Penn State University Libraries was one of the first NDNP grantees and they have received two rounds of supplemental funding; they are the third largest contributor to the site. The three phases of the Pennsylvania Digital Newspaper Project (PaDNP) are described on a Penn State University Library webpage, while Phase I and Phase II are also documented through blogs hosted at PSU.[19] These blogs, taken together with Penn State’s grant proposals, press releases, and NDNP program digitization guidelines, provide unique insight into the processes through the Lewisburg Chronicle, a rural paper from Union County, came to be collected in CA while nineteenth-century Philadelphia is represented by a single newspaper, the Evening Telegraph.
In short, Penn State’s plans for digitization emphasized certain kinds of geographic and demographic representativeness over others. Under their Phase I grant of $393,650, for instance, the group digitized Pennsylvania newspapers published between 1880 and 1922. The newspapers chosen were “currently on microfilm” and were selected by Penn State in consultation with the State Library of Pennsylvania and the Free Library of Philadelphia. These stakeholders used census data to identify the 10 cities with the largest populations between 1880–1922. From these cities, “48 publications were reviewed for initial consideration, with the final selection made by an advisory board of researchers, scholars, librarians and historians.”
Penn State’s Phase II grant of $393,489 expanded the project’s time frame to 1836–1922 while “title selection efforts focused on 17 Pennsylvania counties without any known digitized newspapers.” In Phase II they digitized 45 new titles from the State Library of Pennsylvania, the Free Library of Philadelphia, Bloomsburg University Library, and the Pennsylvania Historical and Museum Commission.
Finally, Penn State’s Phase III grant of $321,526 allowed the group to digitize 109,025 pages from 39 newspapers published between 1836–1922. The foci for this round included: “Titles from four counties with very little or no digitization,” “Tiles that represent the Commonwealth’s German and Italian ethnic heritage,” and “Titles that cover World War I and the Spanish influenza epidemic.”[20]
Over their three rounds of funding, then, Penn State sought to digitize newspapers from as many counties as possible, meaning they prioritized breadth of geographic coverage over digitizing the “most influential” newspapers in the state, which might have produced a corpus skewed in another way: toward Philadelphia over more rural areas in the state.
Phase II’s blog includes a graph and map outlining the state of newspaper digitization in Pennsylvania at the time of that work.
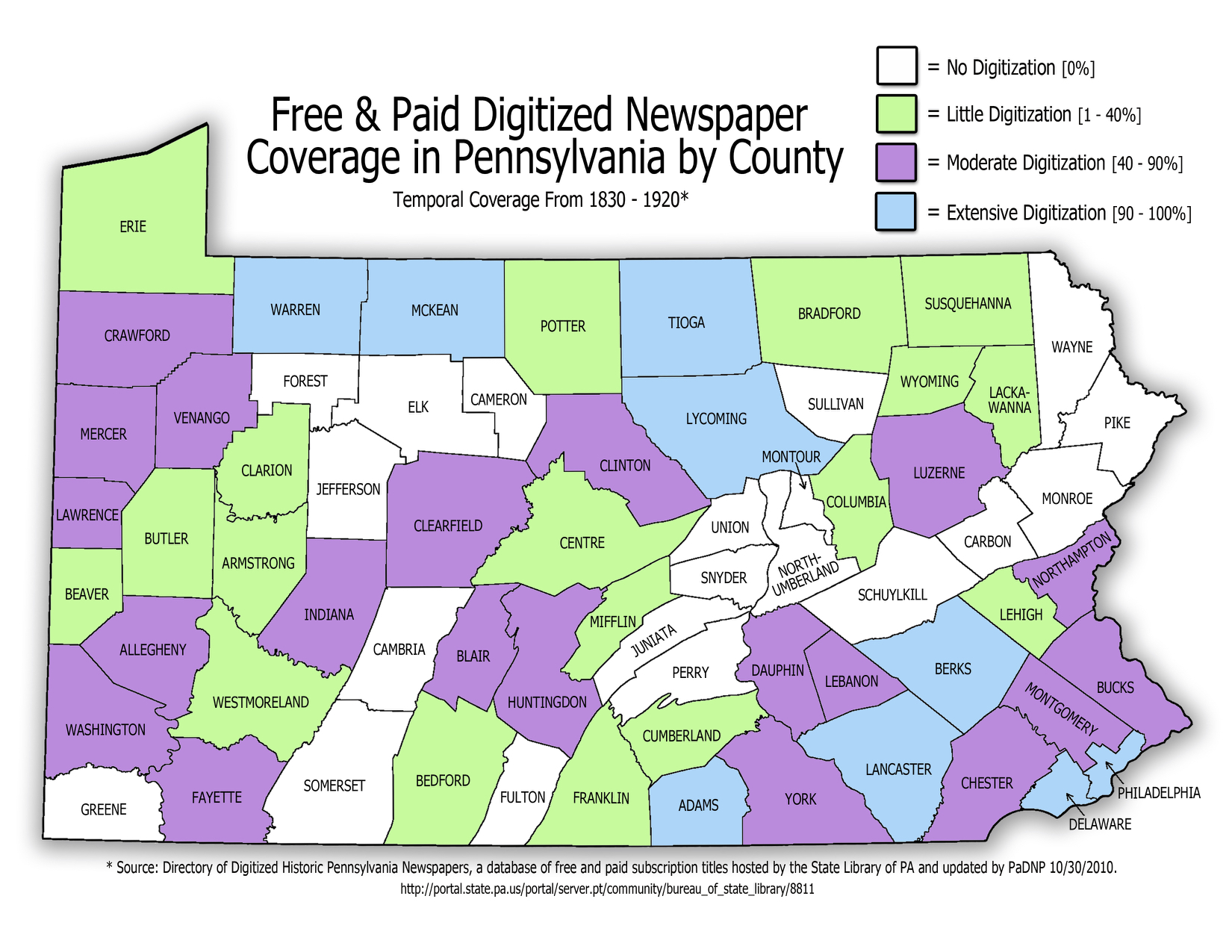
Map of historical newspaper digitization for Pennsylvania as of 2010, prepared for the Pennsylvania Digital Newspaper Program.
The Lewisburg Chronicle, and the West Branch Farmer was scanned in Phase II because Union County had been ignored by previous efforts, both public and commercial. Reading the narrative about the Lewisburg Chronicle, prepared for the PaNDP and now provided on CA, we understand that the paper was chosen among those published in Union Country because of its stability, as “At least eight early Lewisburg weeklies came and went between 1824 and 1842” before the Chronicle brought a regular publication to the county.[21]
I cite these details neither to defend nor deride the choices made by PaDNP. Given finite time and resources, any mass digitization effort must privilege certain features from all possible corpora over others. But understanding these choices is essential for researchers building arguments, computational or otherwise, from CA or its subsidiary archives. An understanding of the corpus’s outlines and the technical composition of its materials allows us to qualify the claims we make using CA while benefiting from the remarkable possibilities of access, comparison, or analytical scale enabled by digitization. Beginning from the specific example of the Lewisburg Weekly helps illustrate how the constitution and provenance of digitized archives are, to some extent at least, knowable and describable. Just as details of type, ink, or paper—or paratext such as printer’s records—can help us establish the histories under which a printed book was created, details of format, interface, and even grant proposals can help us establish the histories of corpora created under conditions of mass digitization.
Acknowledging digitized historical texts as new editions is an important step, I would argue, to developing media-specific approaches to the digital that more effectively exploit its affordances; more responsibly represent the material, social, and economic circumstances of its production; and more carefully delineate with its limitations. To put it more bluntly, I worry that when we treat the digitized object primarily as a surrogate for its analog original, we jettison the best features of both modes. Few researchers have remediated their methodologies toward the digital archive’s unique affordances for pattern detection across vast fields. We largely haven’t learned how to ask pressing humanities questions best answered through computational means. That, I would argue, is the primary challenge facing media historians in our moment—not a technical challenge, but a challenge of imagination.
- Matthew Kirschenbaum, “Text Messaging,” in Mechanisms: New Media and the Forensic Imagination (Cambridge, MA: MIT Press, 2008). ↩
- Bonnie Mak, “Archaeology of a Digitization,” Journal of the Association for Information Science and Technology 65. 8 (August 2014): 1515. ↩
- W. W. Greg, “Bibliography—an Apologia,” in Collected Papers, ed. J. C. Maxwell (Oxford: Clarendon Press, 1966), 257, 259. ↩
- Juxta Commons, http://juxtacommons.org/ ↩
- McDonough, Jerome, Matthew Kirschenbaum, Doug Reside, Neil Fraistat, and Dennis Jerz; “Twisty Little Passages Almost All Alike: Applying the FRBR Model to a Classic Computer Game”; Digital Humanities Quarterly 4. 2 (2010), http://www.digitalhumanities.org/dhq/vol/4/2/000089/000089.html ↩
- Terry Belanger, “Descriptive Bibliography,” in Book Collecting: A Modern Guide, ed. Jean Peters (New York: R. R. Bowker, 1977), 97. ↩
- Johannes Trithemius, In Praise of Scribes, ed. Klaus Arnold, trans. Roland Behrent (Lawrence, KS: Coronado Press, 1974), 65. ↩
- Alan Liu, “Imagining the New Media Encounter,” in A Companion to Digital Literary Studies, ed. Susan Schreibman and Ray Siemens (Oxford: Blackwell, 2008), http://www.digitalhumanities.org/companion/view?docId=blackwell/9781405148641/9781405148641.xml&chunk.id=ss1–3–1 ↩
- The body of OCR research is too broad to succinctly cite here, but the main conference in the field is ICDAR (International Conference on Document Analysis and Recognition), http://2015.icdar.org/, with relevant work often presented—and collected in the conference proceedings of—CVPR (Computer Vision and Pattern Recognition), EMNLP (Empirical Methods in Natural Language Processing), SIGIR (Special Interest Group in Information Retrieval), and NIPS (Neural Information Processing Systems). To cite only a few papers that focus on OCR of historical texts, interested readers might see Garrette et al, “Unsupervised Code-Switching for Multilingual Historical Document Transcription,” NAACL 2015, http://www.aclweb.org/anthology/N/N15/N15–1109.pdf; Lund et al, “How Well Does Multiple OCR Error Correction Generalize?” DRR 2014, http://www.researchgate.net/publication/260084914_How_Well_Does_Multiple_OCR_Error_Correction_Generalize; or Breuer et al, "High-Performance OCR for printed English and Fraktur using LSTM networks,” ICDAR 2013, http://citeseerx.ist.psu.edu/viewdoc/download?doi=10.1.1.433.4006&rep=rep1&type=pdf. ↩
- http://chroniclingamerica.loc.gov/awardees/pst/ and http://chroniclingamerica.loc.gov/batches/batch_pst_fenske_ver02/. ↩
- Exiftool, Phil Harvey, http://www.sno.phy.queensu.ca/~phil/exiftool/, downloaded 10 December 2015. ↩
- CA’s technical guidelines have shifted over time, but scholars can access each version, depending on the date their issue of interest was digitized: * Technical Guidelines for 2007 and 2008 Awards, http://www.loc.gov/ndnp/guidelines/archive/techspecs0708.html * Technical Guidelines for 2009 and 2010 Awards, http://www.loc.gov/ndnp/guidelines/archive/techspecs09.html * Technical Guidelines for 2012 Awards, http://www.loc.gov/ndnp/guidelines/archive/guidelines1213.html ↩
- The Eclipse 300 Microfilm Scanner was released by nextScan in 2009, http://www.nextscan.com/nextscan-introduces-the-eclipse-plus-high-production-rollfilm-scanner-with-lumintec-light-line-illumination-system/#.VRF8DVxCNFI. ↩
- XML is a markup language, like the more familiar HTML (HyperText markup Language) that underlies most webpages. XML’s primary use is to storing data in a format that is both human- and machine-readable. The most familiar version XML in the humanities is the TEI, or Text Encoding Initiative, which is a group “whose mission is to develop and maintain guidelines for the digital encoding of literary and linguistic texts.” “About the TEI,” http://www.tei-c.org/About/. ↩
- Because Abbyy Finereader is a commercial product, the software that predicts its accuracy is not freely available for inspection. As such, we should not make too much of the figure presented here, which certainly does not align with a human reader’s assessment of the page’s overall similarity to the words on the page images. ↩
- In October of 2010 iArchives was acquired by Ancestry.com (http://Ancestry.com), and their technologies essentially became the for-profit Newspapers.com (http://Newspapers.com) that feeds many of the results you get when searching family trees in Ancestry. ↩
- Ian Milligan, “Illusionary Order: Online Databases, Optical Character Recognition, and Canadian History, 1997–2010,” Canadian Historical Review 94.4 (December 2013): 550, 567. ↩
- Jamie Mears, National Digital Newspaper Program Impact Study 2004–2014, National Endowment for the Humanities (September 2014), https://www.loc.gov/ndnp/guidelines/docs/ndnp_report_2014_0.pdf. ↩
- An overview of the PaDNP’s three phases can be found at https://www.libraries.psu.edu/psul/digipres/panp/padnp.html, while production blogs for Phase I and Phase II can be found at http://www.personal.psu.edu/kkm111/blogs/pa_digital_newspaper_project/ and http://www.personal.psu.edu/kkm111/blogs/padnp2/, respectively. As a side note, I would express some hope that Penn State University Libraries will take care to preserve these resources, which are valuable bibliographic assets for researchers using the CA corpus. ↩
- All figures taken from https://www.libraries.psu.edu/psul/digipres/panp/padnp.html. ↩
- This narrative can be found at http://chroniclingamerica.loc.gov/lccn/sn85055199/. ↩